On This Page:ToggleTest-RetestInter-RaterInternal ConsistencyValidity vs. Reliability
On This Page:Toggle
On This Page:
Reliability in psychology research refers to the reproducibility or consistency of measurements. Specifically, it is the degree to which a measurement instrument or procedure yields the same results on repeated trials. A measure is considered reliable if it produces consistent scores across different instances when the underlying thing being measured has not changed.
Reliability ensures that responses are consistent across times and occasions for instruments likequestionnaires. Multiple forms of reliability exist, including test-retest, inter-rater, and internal consistency.
For example, if people weigh themselves during the day, they would expect to see a similar reading. Scales that measured weight differently each time would be of little use.
The same analogy could be applied to a tape measure that measures inches differently each time it is used. It would not be considered reliable.
If findings from research are replicated consistently, they are reliable. A correlation coefficient can be used to assess the degree of reliability. If a test is reliable, it should show a high positive correlation.
Of course, it is unlikely the same results will be obtained each time as participants and situations vary. Still, a strong positive correlation between the same test results indicates reliability.
Reliability is important because unreliable measures introduce random error that attenuates correlations and makes it harder to detect real relationships.
Ensuring high reliability for key measures in psychology research helps boost the sensitivity, validity, and replicability of studies. Estimating and reporting reliable evidence is considered an important methodological practice.
There are two types of reliability: internal and external.Internal reliabilityrefers to how consistently different items within a single test measure the same concept or construct. It ensures that a test is stable across its components.External reliabilitymeasures how consistently a test produces similar results over repeated administrations or under different conditions. It ensures that a test is stable over time and situations.
There are two types of reliability: internal and external.

Some key aspects of reliability in psychology research include:
Test-Retest Reliability
The test-retest method assesses the external consistency of a test. Examples of appropriate tests include questionnaires and psychometric tests. It measures the stability of a test over time.
A typical assessment would involve giving participants the same test on two separate occasions. If the same or similar results are obtained, then external reliability is established.
This method is especially useful for tests that measure stable traits or characteristics that aren’t expected to change over short periods.
Beck et al. (1996) studied the responses of 26 outpatients on two separate therapy sessions one week apart, they found a correlation of .93 therefore demonstrating high test-restest reliability of the depression inventory.
This is an example of why reliability in psychological research is necessary, if it wasn’t for the reliability of such tests some individuals may not be successfully diagnosed with disorders such as depression and consequently will not be given appropriate therapy.
The timing of the test is important; if the duration is too brief, then participants may recall information from the first test, which could bias the results.
Alternatively, if the duration is too long, it is feasible that the participants could have changed in some important way which could also bias the results.
The test-retest method assesses the external consistency of a test. This refers to the degree to which different raters give consistent estimates of the same behavior. Inter-rater reliability can be used for interviews.
Inter-Rater Reliability
Inter-rater reliability, often termed inter-observer reliability, refers to the extent to which different raters or evaluators agree in assessing a particular phenomenon, behavior, or characteristic. It’s a measure of consistency and agreement between individuals scoring or evaluating the same items or behaviors.
High inter-rater reliability indicates that the findings or measurements are consistent across different raters, suggesting the results are not due to random chance or subjective biases of individual raters.
Statistical measures, such as Cohen’s Kappa or the Intraclass Correlation Coefficient (ICC), are often employed to quantify the level of agreement between raters, helping to ensure that findings are objective and reproducible.
Note it can also be called inter-observer reliability when referring to observational research. Here, researchers observe the same behavior independently (to avoid bias) and compare their data. If the data is similar, then it is reliable.
For example, if two researchers are observing ‘aggressive behavior’ of children at nursery they would both have their own subjective opinion regarding what aggression comprises.
In this scenario, they would be unlikely to record aggressive behavior the same, and the data would be unreliable.
However, if they were to operationalize the behavior category of aggression, this would be more objective and make it easier to identify when a specific behavior occurs.
For example, while “aggressive behavior” is subjective and not operationalized, “pushing” is objective and operationalized. Thus, researchers could count how many times children push each other over a certain duration of time.
Internal Consistency Reliability
Internal consistency reliability refers to how well different items on a test or survey that are intended to measure the same construct produce similar scores.
For example, a questionnaire measuring depression may have multiple questions tapping issues like sadness, changes in sleep and appetite, fatigue, and loss of interest. The assumption is that people’s responses across these different symptom items should be fairly consistent.
Cronbach’s alpha is a common statistic used to quantify internal consistency reliability. It calculates the average inter-item correlations among the test items. Values range from 0 to 1, with higher values indicating greater internal consistency. A good rule of thumb is that alpha should generally be above .70 to suggest adequate reliability.
An alpha of .90 for a depression questionnaire, for example, means there is a high average correlation between respondents’ scores on the different symptom items.
This suggests all the items are measuring the same underlying construct (depression) in a consistent manner. It taps the unidimensionality of the scale – evidence it is measuring one thing.
If some items were unrelated to others, the average inter-item correlations would be lower, resulting in a lower alpha. This would indicate the presence of multiple dimensions in the scale, rather than a unified single concept.
So, in summary, high internal consistency reliability evidenced through high Cronbach’s alpha provides support for the fact that various test items successfully tap into the same latent variable the researcher intends to measure. It suggests the items meaningfully cohere together to reliably measure that construct.
Split-Half Method
The split-half method assesses the internal consistency of a test, such as psychometric tests and questionnaires.
There, it measures the extent to which all parts of the test contribute equally to what is being measured.
It’s somewhat cumbersome to implement but avoids limitations associated with Cronbach’s alpha. However, alpha remains much more widely used in practice due to its relative ease of calculation.
The split-half method is a quick and easy way to establish reliability. However, it can only be effective with large questionnaires in which all questions measure the same construct. This means it would not be appropriate for tests that measure different constructs.
For example, theMinnesota Multiphasic Personality Inventoryhas sub scales measuring differently behaviors such as depression, schizophrenia, social introversion. Therefore the split-half method was not be an appropriate method to assess reliability for this personality test.
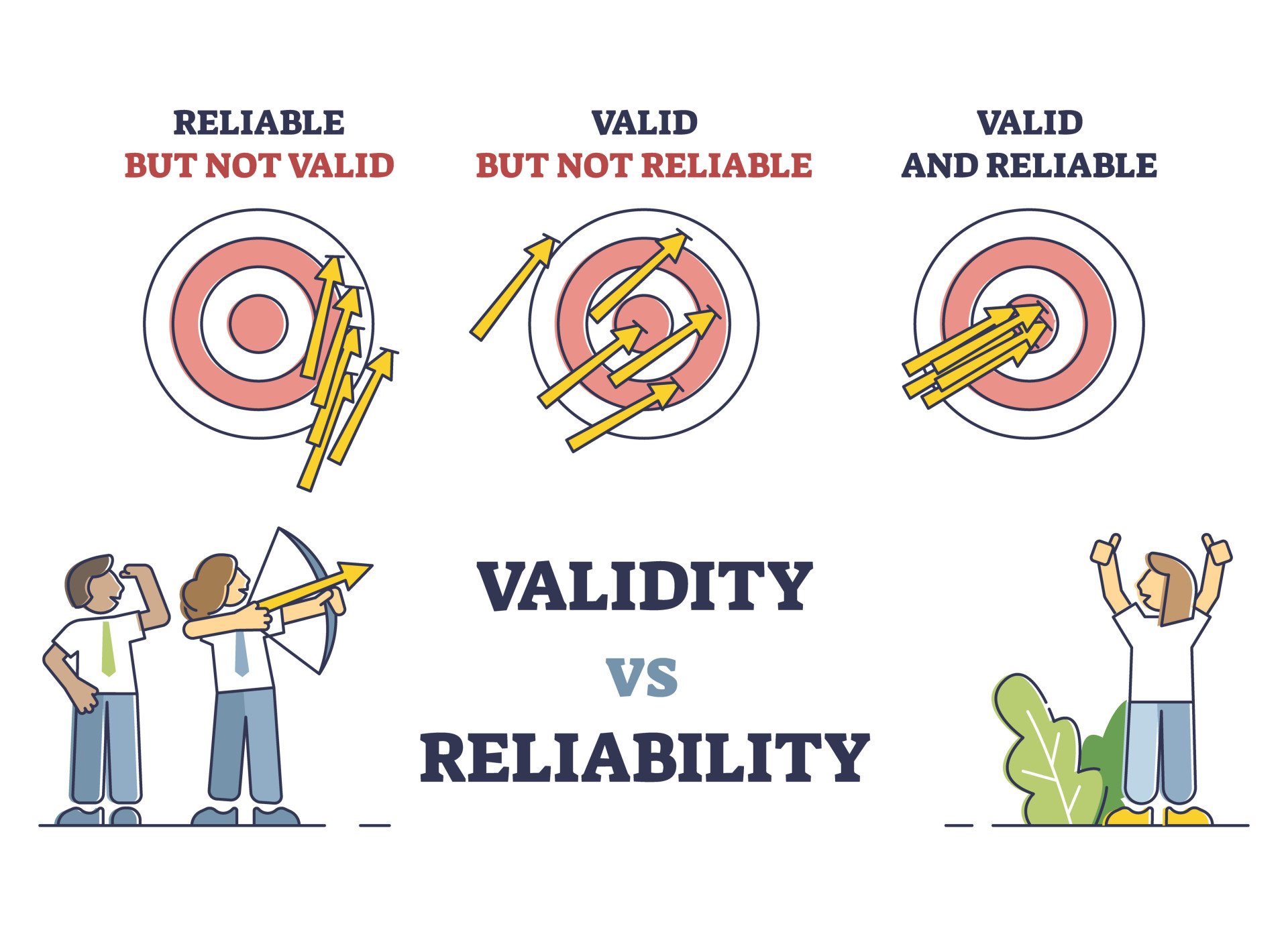
Validity vs. Reliability In Psychology
In psychology,validity and reliabilityare fundamental concepts that assess the quality of measurements.
A key difference is thatvalidityrefers to what’s being measured, while reliability refers to how consistently it’s being measured.
An unreliable measure cannot be truly valid because if a measure gives inconsistent, unpredictable scores, it clearly isn’t measuring the trait or quality it aims to measure in a truthful, systematic manner. Establishing reliability provides the foundation for determining the measure’s validity.
A pivotal understanding is that reliability is a necessary but not sufficient condition for validity.
It means a test can be reliable, consistently producing the same results, without being valid, or accurately measuring the intended attribute.
However, a valid test, one that truly measures what it purports to, must be reliable. In the pursuit of rigorous psychological research, both validity and reliability are indispensable.
Ideally, researchers strive for high scores on both -Validity to make sure you’re measuring the correct construct and reliability to make sure you’re measuring it accurately and precisely. The two qualities are independent but both crucial elements of strong measurement procedures.
References
Beck, A. T., Steer, R. A., & Brown, G. K. (1996). Manual for the beck depression inventory The Psychological Corporation.San Antonio, TX.
Clifton, J. D. W. (2020). Managing validity versus reliability trade-offs in scale-building decisions.Psychological Methods, 25(3), 259–270.https:// doi.org/10.1037/met0000236
Guttman, L. (1945). A basis for analyzing test-retest reliability.Psychometrika, 10(4), 255–282.https://doi.org/10.1007/BF02288892
Hathaway, S. R., & McKinley, J. C. (1943).Manual for the Minnesota Multiphasic Personality Inventory. New York: Psychological Corporation.
Jannarone, R. J., Macera, C. A., & Garrison, C. Z. (1987). Evaluating interrater agreement through “case-control” sampling.Biometrics, 43(2), 433–437.https://doi.org/10.2307/2531825
LeBreton, J. M., & Senter, J. L. (2008). Answers to 20 questions about interrater reliability and interrater agreement.Organizational Research Methods, 11(4), 815–852.https://doi.org/10.1177/1094428106296642
Watkins, M. W., & Pacheco, M. (2000). Interobserver agreement in behavioral research: Importance and calculation.Journal of Behavioral Education, 10, 205–212
![]()
Olivia Guy-Evans, MSc
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
Saul McLeod, PhD
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
